

张娇娇1 · 户将2 · Mikael Johansson3
1大湾区大学 2清华大学求真学院 3瑞典皇家理工学院(KTH)
摘要
我们提出了一种新颖算法,用于求解含非光滑正则项的非凸复合联邦学习问题。该算法通过解耦邻近算子与通信以处理非光滑项,无需任何数据相似性假设仍可克服节点漂移;节点执行多步本地更新以降低通信频率,且每轮仅需传输一个d维向量。我们严格证明了算法的收敛精度与速率,并通过数值实验验证了其有效性。
研究背景
联邦学习是当前主流的分布式机器学习框架:中心服务器协调多个工作节点在不共享本地数据的情况下协作训练全局模型,广泛应用于机器学习、无线网络和物联网等领域。
与传统分布式学习相比,联邦学习面临更严重的通信瓶颈以及节点间数据异构的挑战。经典的联邦平均算法(FedAvg)通过让各节点在上传前执行多次本地更新来降低通信频率,但在数据异构时会出现明显的节点漂移问题,导致求解精度下降。
现有改进方法(如 SCAFFOLD、Mime)虽能缓解漂移,但往往需要额外传输控制变量,增加了通信成本。此外,大多数已有算法仅处理光滑优化问题,而实际中频繁出现含约束条件或稀疏/低秩约束的非光滑目标函数。本工作正是针对这一空白展开研究。
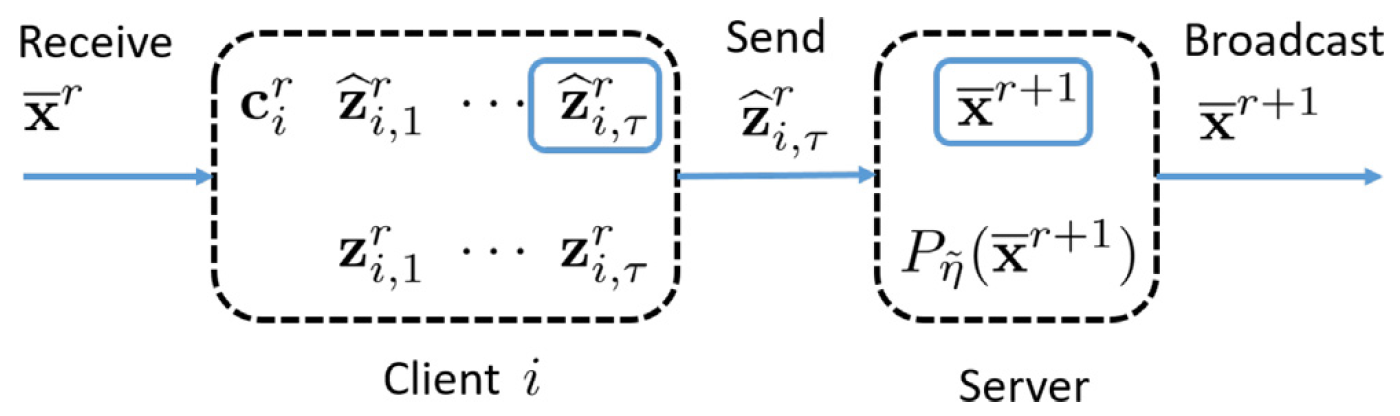
图1:所提算法的工作流程
核心贡献
我们提出的算法针对如下复合联邦学习问题:最小化光滑(可能非凸)损失函数与凸非光滑正则项之和,且不对各节点本地数据分布作任何相似性假设。所提算法的工作流程如图1所示。算法的四大关键优势如下:
▸ 解耦邻近算子与通信: 每个节点维护操作前后两个变量,将邻近算子计算与通信步骤彻底解耦。节点仅需将未经邻近操作的中间变量上传至服务器,服务器即可提取各节点的平均梯度信息,从而正确驱动全局模型更新。
▸ 消除节点漂移: 每次本地更新引入轻量校正项,将全局梯度信息融入本地更新方向,使每个节点的优化目标与全局目标保持一致,从根本上消除异构数据带来的漂移偏差。
▸ 低通信开销: 与 SCAFFOLD、Mime 等需要额外上传控制变量的方法不同,本算法每轮通信每个节点仅交换一个 d 维向量,通信量与 FedAvg 相当,却具有更强的理论保证。
▸ 严格收敛性分析: 在强凸、一般非凸以及 Proximal Polyak–Łojasiewicz(PL)条件下,均给出了收敛精度与速率的完整理论证明。
数值实验
我们在带 ℓ₁ 正则项的 MNIST 手写数字分类任务上对所提算法进行了验证,使用 CNN 模型,在三种数据异构程度(60%、80%、90%)以及两种本地更新步数(τ = 5 和 τ = 10)下与基线方法 FedDA 进行对比。
表:MNIST 分类准确率(%)对比结果
|
算法 |
τ = 5 |
τ = 10 |
||||
|
60% |
80% |
90% |
60% |
80% |
90% |
|
|
本文算法(Ours) |
96.0 |
96.2 |
96.2 |
96.3 |
96.3 |
96.3 |
|
FedDA |
94.7 |
92.5 |
89.7 |
94.1 |
91.1 |
86.2 |
|
相对提升 |
+1.3% |
+3.7% |
+6.5% |
+2.2% |
+5.2% |
+10.1% |
结果表明,本文算法在不同异构程度和本地更新步数下均保持稳定的高准确率。尤其在高异构场景(90%)下,τ = 5 时相对提升 6.5 个百分点,τ = 10 时相对提升高达 10.1 个百分点,充分验证了算法在处理异构数据时的显著优势。
[1] Jiaojiao Zhang, Jiang Hu, and Mikael Johansson. Non-convex composite federated learning with heterogeneous data. Automatica, 183:112695, 2026.













