

东莞市大湾区高等研究院智能计算研究中心、大湾区大学信息科学技术学院刘洋助理教授与牛津大学数学系Coralia Cartis教授、Raphael Hauser教授、Karl Welzel博士、Wenqi Zhu博士合作,在非凸无约束优化的三阶张量方法高效实现方面取得重要进展。相关成果以“Efficient Implementation of Third-order Tensor Methods with Adaptive Regularization for Unconstrained Optimization”为题,发表于数值优化领域重要期刊Mathematical Programming Computation(MPC, 2026)。该期刊由国际数学优化学会(MOS)主办,所发表的论文均要求附带源代码与可复现实验,在JCR应用数学和软件工程两个类别下均为Q1期刊。刘洋为论文唯一通讯作者兼共同第一作者,大湾区大学为论文唯一通讯单位。
在最坏条件复杂度理论中,使用更高阶导数信息的优化方法通常所需的外层算法迭代次数更少。然而,这一理论优势能否在一般非凸问题上稳定兑现,长期缺少系统性的经验证据。具体而言,从算法的综合代价(如函数与导数调用次数、子问题求解次数等)来看,三阶方法是否能稳定胜过成熟的二阶方法,也尚无系统的实证答案。团队在这项工作中重新审视了三阶以及更高阶方法,识别出制约其实际效率的两个核心问题。
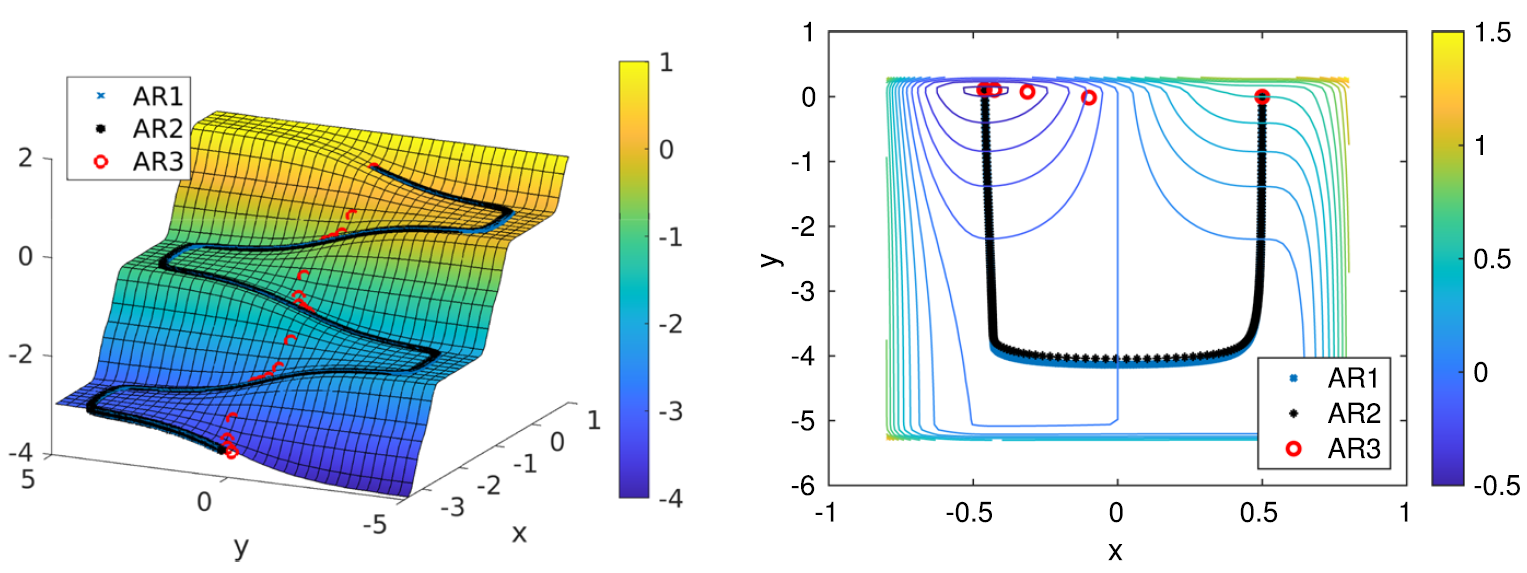
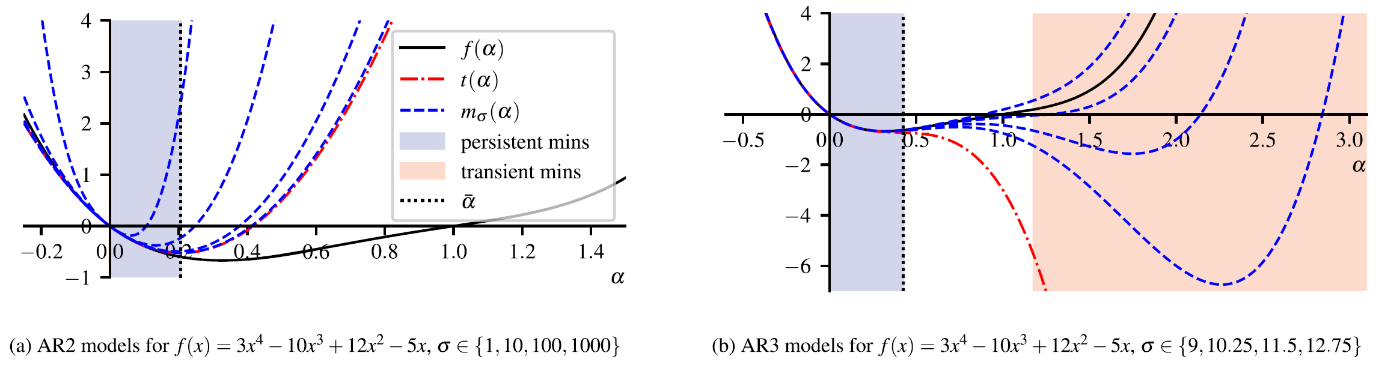
其一,团队发现并刻画了一类新颖的高阶算法机理。在三阶及以上的正则化子问题中,以子问题全局最优解为代表的部分极小点(称为“瞬态极小点”),可能随正则化参数的增大而消失;另一部分极小点(称为“恒态极小点”)则在出现后稳定变化。作为对照,二阶方法的子问题全局最优解永远是恒态的,这是二阶方法长期稳健的一个隐性保障;然而该保障不适用于三阶及以上方法。基于对这两类极小点的严格区分,团队系统地设计了一种预拒绝机制,使算法在调用目标函数求值之前即可识别并剔除沿瞬态方向的试探步,显著降低了数值上体现为无效的迭代次数。
其二,团队初步给出了应对高阶算法高额存储需求的技术方案。显式存储三阶张量的内存代价为O(d³),以维度d=16,384的问题为例,这意味着需要约32TB的内存空间去储存单个三阶张量,远超普通工作站的承载能力。团队采用基于Krylov子空间的迭代求解器,实现了三阶方法的无矩阵、无张量(Hessian-free & tensor-free)架构,算法全程只需调用Hessian-向量乘积与三阶张量-向量-向量乘积,无需显式存储完整的Hessian矩阵与三阶张量。这将内存需求从O(d³)降至O(d),使原本需32TB显式存储的问题可以在普通工作站上求解。
除上述两项主要贡献之外,团队还将[Gould, Porcelli and Toint, Comput. Optim. Appl. (2012) 53:1–22]中针对二阶方法提出的一维插值型正则化参数更新策略推广到任意p阶(p≥2)情形,使自适应参数更新在三阶及以上方法中同样适用。整合了上述方法的新算法在35个Moré-Garbow-Hillstrom经典测试问题上的基准评测中,于函数求值、导数求值、子问题求解三项指标上均优于标准的二阶方法。
本工作标志着两件事:其一,团队首次系统刻画了三阶及以上子问题中恒态极小点与瞬态极小点的区分,它既是预拒绝机制的理论基础,也为后续高阶方法的设计提供了新的研究角度。在三阶及以上方法中,盲目追求子问题的全局最优并不总是必要的;更关键的是选到合适的局部极小点;这一推论也在我们的数值实验中得到了印证:高阶方法中的有效迭代步无需依赖代价昂贵的子问题全局求解,仅靠局部求解配合对极小点的区分即可获得,从而为可扩展性提供了依据。其二,团队已初步具备应对高阶算法高额存储需求的技术方案,无矩阵、无张量的实现方案让三阶方法首次可被应用到维度过万的大规模问题上。综合这两项贡献,本工作在理论分析与算法实现两个层面,为高阶优化方法的进一步探索提供了新的视角与工具。
该研究得到香港创新科技署(InnoHK Project CIMDA)的资助;Coralia Cartis教授与Raphael Hauser教授另由英国EPSRC项目EP/Y028872/1“智能的数学基础:面向AI的‘埃尔朗根纲领’”(Mathematical Foundations of Intelligence: An "Erlangen Programme" for AI)资助。
论文链接:https://doi.org/10.1007/s12532-026-00313-6
代码开源:https://github.com/karlwelzel/ar3-matlab













